

DNS
什么是DNS
域名系统(英语:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
简单来说就是用域名请求服务器换回来ip地址
这个网站可以看dns请求的结果、同理还有linux或者windows的nslookup命令
DNS records for dn11.top
A records
| IPv4 address | Revalidate in |
|---|---|
| 104.21.27.178 | 5m |
| 172.67.143.107 | 5m |
DNS 服务器使人们无需存储复杂记不住的ip地址,而是记住有规律的域名来方便的访问互联网
DNS记录
DNS 记录是位于权威 DNS 服务器中的指令,提供一个域的相关信息,包括哪些 IP 地址与该域关联,以及如何处理对该域的请求。
常见的 DNS 记录
SOA 记录 - 存储域的管理信息。
;; ANSWER SECTION:
dn11.top. 1800 IN SOA ophelia.ns.cloudflare.com. dns.cloudflare.com. 2322082117 10000 2400 604800 1800
NS 记录 - 存储 DNS 条目的名称服务器。
;; ANSWER SECTION:
dn11.top. 21600 IN NS ophelia.ns.cloudflare.com.
dn11.top. 21600 IN NS phil.ns.cloudflare.com.
A 记录 - 保存域的 IPv4 地址的记录。
;; ANSWER SECTION:
dn11.top. 300 IN A 104.21.27.178
dn11.top. 300 IN A 172.67.143.107
AAAA 记录 - 包含域的 IPv6 地址的记录(与 A 记录相反,A 记录列出的是 IPv4 地址)。
CNAME 记录 - 将一个域或子域转发到另一个域,不提供 IP 地址。
MX 记录 - 将邮件定向到电子邮件服务器。
TXT 记录 - 可让管理员在记录中存储文本注释。这些记录通常用于电子邮件安全。
有几种DNS服务器?有几种工作方式?
有两种DNS服务器:DNS递归服务器和DNS权威服务器
有两种工作方式:递归和迭代
DNS客户端设置使用的DNS服务器一般都是DNS递归服务器,它负责全权处理客户端的DNS查询请求,直到返回最终结果。而DNS服务器之间一般采用迭代查询方式。
如何工作的
DNS查询 涉及 4 个 DNS 服务器:
- DNS 递归解析器
DNS 解析器是一种服务器,旨在通过 Web 浏览器等应用程序接收客户端计算机的查询。然后,解析器一般负责发出其他请求,以便满足客户端的 DNS 查询。
常见的 dns 递归解析器有
谷歌 8.8.8.8 8.8.4.4
阿里 223.5.5.5 223.6.6.6
百度 180.76.76.76
腾讯DNSPod 119.29.29.29
CloudFlare 1.1.1.1
更多 https://en.wikipedia.org/wiki/Public_recursive_name_server
- 根域名服务器
根域名服务器是将主机名转换(解析)为 IP 地址的第一步。
根域名服务器(英语:root name server,简称“根域名服务器”)是互联网域名解析系统(DNS)中最高级别的域名服务器,负责返回顶级域的权威域名服务器地址。
任意正常 linux 发行版可以运行如下命令来看到这13台根域名服务器
ubuntu@ubuntu_dn11:~$ dig ns . @8.8.8.8
; <<>> DiG 9.18.12-0ubuntu0.22.04.3-Ubuntu <<>> ns . @8.8.8.8
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 9453
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 13, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;. IN NS
;; ANSWER SECTION:
. 71928 IN NS a.root-servers.net.
. 71928 IN NS b.root-servers.net.
. 71928 IN NS c.root-servers.net.
. 71928 IN NS d.root-servers.net.
. 71928 IN NS e.root-servers.net.
. 71928 IN NS f.root-servers.net.
. 71928 IN NS g.root-servers.net.
. 71928 IN NS h.root-servers.net.
. 71928 IN NS i.root-servers.net.
. 71928 IN NS j.root-servers.net.
. 71928 IN NS k.root-servers.net.
. 71928 IN NS l.root-servers.net.
. 71928 IN NS m.root-servers.net.
;; Query time: 0 msec
;; SERVER: 8.8.8.8#53(8.8.8.8) (UDP)
;; WHEN: Fri Oct 06 13:22:43 UTC 2023
;; MSG SIZE rcvd: 239
全球13组根域名服务器以英文字母A到M依序命名,域名格式为“字母.root-servers.net”。利用任播(anycast)技术在全球多个地点设立镜像站。
截至2023年6月,全球共有1719台根域名服务器在运行。
Q:为什么是13组?1700组不行吗?
A:由于DNS和某些协议(未分片的用户数据报协议(UDP)数据包在IPv4内的最大有效大小为512字节)的共同限制,根域名服务器地址的数量被限制为13个。一次返回的数据放不下啦~
Q:anycast是什么?
A:我们假设有三台服务器α、β、γ和一台客户机,这三台服务器都宣告了同样的一个地址比如说172.16.255.53,客户机访问172.16.255.53时,会因为路由协议的原因,选择客户机距离服务器最近的一条路径。假设α距离客户机近,访问172.16.255.53获得的数据就是α服务器给客户机的。
Q:anycast的好处?
A:防止服务挂掉、流量会自动寻找最佳路径、假设一台服务器挂掉了,整个服务会被另一台服务器承担。
Q:有 . 这个服务器吗
A:存放这13个根域的是一个文件,它被内置在递归服务器内,没有权威服务器会返回 . 这个域的解析给你。
在这里可以下载到这个文件 https://www.iana.org/domains/root/files
运营商通常需要配置一个 “Root Hints 文件” 来管理 DNS 递归解析器。该文件包含了根区域的权威名称服务器的名称和 IP 地址,以便软件可以引导 DNS 解析过程。对于许多软件来说,这个列表已经内置在软件中。https://www.internic.net/domain/named.root
- TLD 名称服务器
顶级域名(英语:Top-level Domain, TLD)是互联网域名系统的等级中,位于根域空间的最高级域名。
顶级域名服务器这个服务器是搜索特定 IP 地址的下一步,其上托管了主机名的最后一部分(例如,在 dn11.top 中,TLD 服务器为 “top”)。
https://www.iana.org/domains/root/db 这里是世界上完整的顶级域列表。
- 权威性域名服务器
权威性域名服务器是域名服务器查询中的最后一站。
权威名称服务器包含特定于其服务域名的信息(例如,dn11.top)权威性域名服务器包含特定于其所服务的域名的信息(例如 dn11.top),并且它可为递归解析器提供在 DNS A 记录中找到的服务器的 IP 地址(例如找到了上文的ipv4地址 104.21.27.178)
图解工作流程
递归工作流程
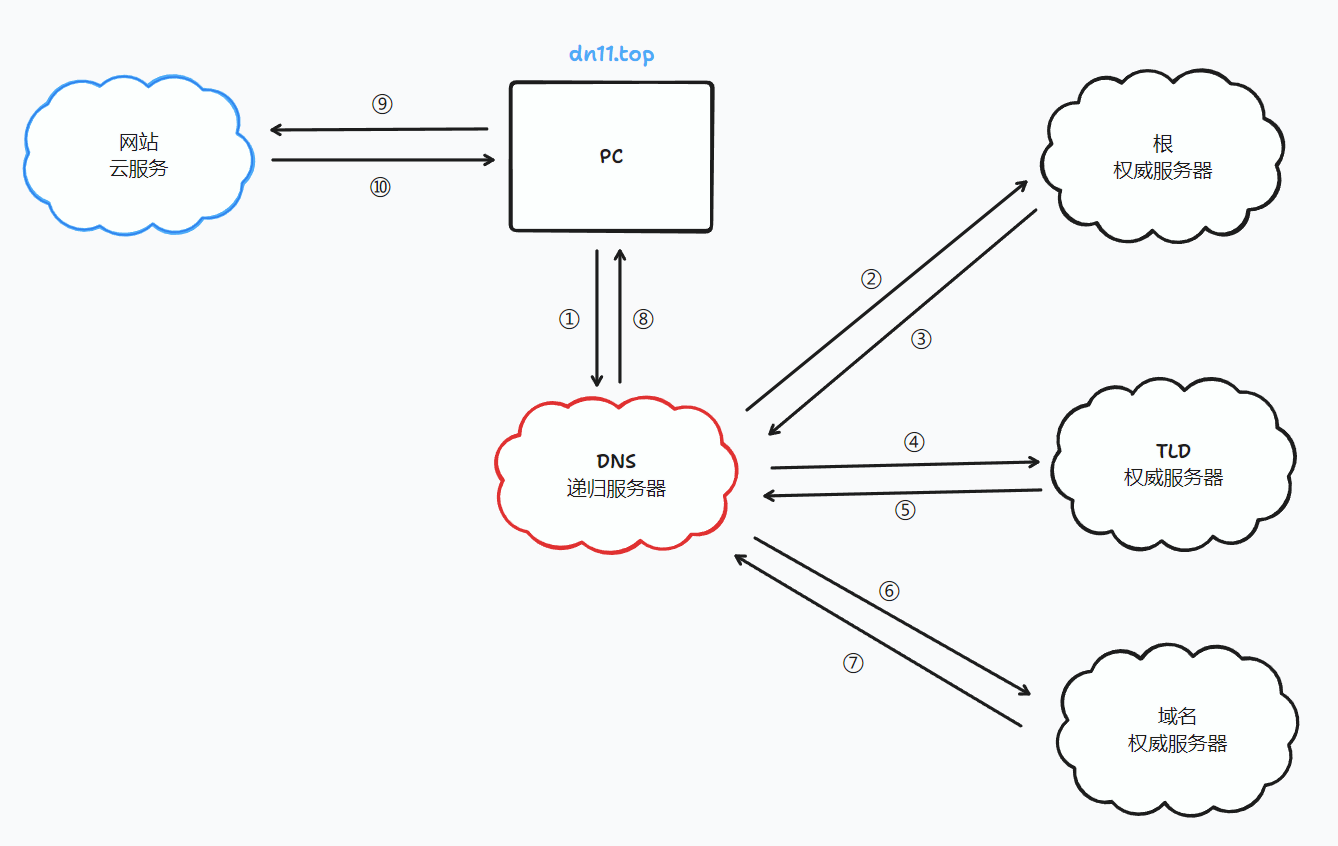
我这里画了一张图:其中红色服务器为DNS递归服务器,PC上的DNS客户端只与DNS递归服务器通讯,由递归服务器完成后续查询内容。蓝色云为想要访问的网站的ip地址所在的服务器。
我会逐一讲解每个过程(箭头)都做了什么。
本图的前提是dns递归服务器中不含任何缓存。
①:PC通过浏览器输入了dn11.top这个域名、dns客户端收到了请求dn11.top这个域名的ip的任务、dns客户端去请求DNS递归服务器
②:DNS递归服务器使用内置的Root Hint文件(内有根服务器的NS解析和根服务器的IP地址)去请求根权威服务器、得到了TLD服务器的NS解析并得到了TLD服务器的ip地址
③:TLD服务器的ip地址被返回给DNS递归服务器
④:DNS递归服务器去请求TLD服务器、得到了域名权威服务器的NS解析并得到了域名权威服务器的NS记录和IP地址
⑤:域名权威服务器的ip地址被返回给DNS递归服务器
⑥:DNS递归服务器去请求域名权威服务器、得到了请求域名最终的ip
⑦:请求域名最终的ip被返回给DNS递归服务器
⑧:请求域名最终的ip被返回给PC上的DNS客户端
⑨:PC上的浏览器用请求域名最终的ip访问域名所在的云服务器
⑩:云服务器返回网页数据给PC浏览器、实现页面的访问
迭代工作流程
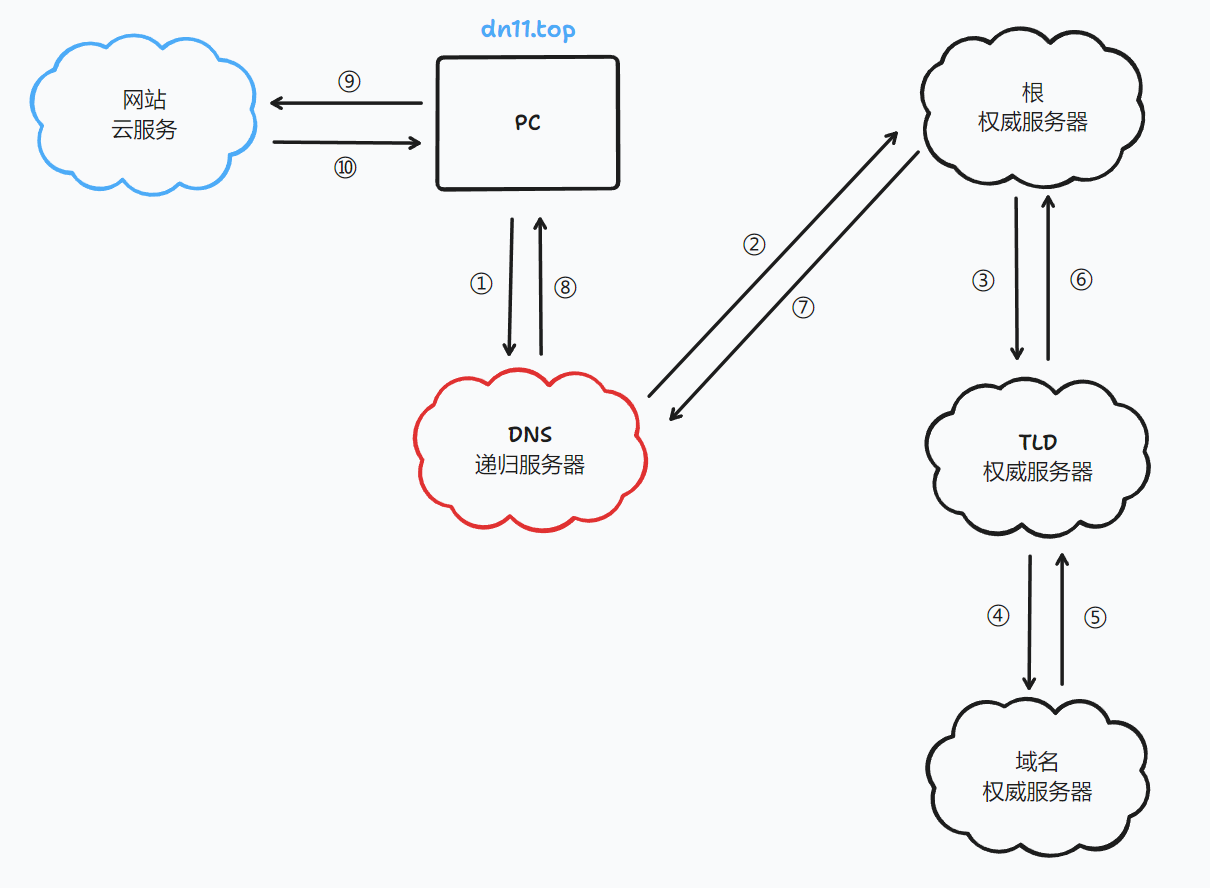
我这里画了一张图:其中红色服务器为DNS递归服务器,PC上的DNS客户端只与DNS递归服务器通讯,由递归服务器和权威服务器的迭代查询完成后续查询内容。蓝色云为想要访问的网站的ip地址所在的服务器。
我会逐一讲解每个过程(箭头)都做了什么。
本图的前提是dns递归服务器中不含任何缓存。
①:PC通过浏览器输入了dn11.top这个域名、dns客户端收到了请求dn11.top这个域名的ip的任务、dns客户端去请求DNS递归服务器
②:DNS递归服务器使用内置的Root Hint文件(内有根服务器的NS解析和根服务器的IP地址)去请求根权威服务器、根权威服务器收到了请求、找到了TLD权威服务器的NS记录和ip地址
③:根权威服务器请求TLD服务器、TLD服务器收到了请求、找到了域名权威服务器的NS记录和ip地址
④:TLD服务器请求域名权威服务器、权威服务器找到了域名的ip地址
⑤:域名的ip地址从域名权威服务器返回给TLD权威服务器
⑥:域名的ip地址从TLD权威服务器返回给根权威服务器
⑦:域名的ip地址从根权威返回给DNS递归服务器
⑧:请求域名最终的ip被返回给PC上的DNS客户端
⑨:PC上的浏览器用请求域名最终的ip访问域名所在的云服务器
⑩:云服务器返回网页数据给PC浏览器、实现页面的访问
配置pdns
1.openwrt直接启动
装包
opkg update
opkg install pdns pdns-backend-sqlite3 pdns-recursor sqlite3-cli
初始化数据库
创建文件
mkdir -p /usr/share/doc/pdns-backend-sqlite/
touch schema.sqlite3.sql
然后在schema.sqlite3.sql里写入
nano /usr/share/doc/pdns-backend-sqlite/schema.sqlite3.sql
PRAGMA foreign_keys = 1;
CREATE TABLE domains (
id INTEGER PRIMARY KEY,
name VARCHAR(255) NOT NULL COLLATE NOCASE,
master VARCHAR(128) DEFAULT NULL,
last_check INTEGER DEFAULT NULL,
type VARCHAR(8) NOT NULL,
notified_serial INTEGER DEFAULT NULL,
account VARCHAR(40) DEFAULT NULL,
options VARCHAR(65535) DEFAULT NULL,
catalog VARCHAR(255) DEFAULT NULL
);
CREATE UNIQUE INDEX name_index ON domains(name);
CREATE INDEX catalog_idx ON domains(catalog);
CREATE TABLE records (
id INTEGER PRIMARY KEY,
domain_id INTEGER DEFAULT NULL,
name VARCHAR(255) DEFAULT NULL,
type VARCHAR(10) DEFAULT NULL,
content VARCHAR(65535) DEFAULT NULL,
ttl INTEGER DEFAULT NULL,
prio INTEGER DEFAULT NULL,
disabled BOOLEAN DEFAULT 0,
ordername VARCHAR(255),
auth BOOL DEFAULT 1,
FOREIGN KEY(domain_id) REFERENCES domains(id) ON DELETE CASCADE ON UPDATE CASCADE
);
CREATE INDEX records_lookup_idx ON records(name, type);
CREATE INDEX records_lookup_id_idx ON records(domain_id, name, type);
CREATE INDEX records_order_idx ON records(domain_id, ordername);
CREATE TABLE supermasters (
ip VARCHAR(64) NOT NULL,
nameserver VARCHAR(255) NOT NULL COLLATE NOCASE,
account VARCHAR(40) NOT NULL
);
CREATE UNIQUE INDEX ip_nameserver_pk ON supermasters(ip, nameserver);
CREATE TABLE comments (
id INTEGER PRIMARY KEY,
domain_id INTEGER NOT NULL,
name VARCHAR(255) NOT NULL,
type VARCHAR(10) NOT NULL,
modified_at INT NOT NULL,
account VARCHAR(40) DEFAULT NULL,
comment VARCHAR(65535) NOT NULL,
FOREIGN KEY(domain_id) REFERENCES domains(id) ON DELETE CASCADE ON UPDATE CASCADE
);
CREATE INDEX comments_idx ON comments(domain_id, name, type);
CREATE INDEX comments_order_idx ON comments (domain_id, modified_at);
CREATE TABLE domainmetadata (
id INTEGER PRIMARY KEY,
domain_id INT NOT NULL,
kind VARCHAR(32) COLLATE NOCASE,
content TEXT,
FOREIGN KEY(domain_id) REFERENCES domains(id) ON DELETE CASCADE ON UPDATE CASCADE
);
CREATE INDEX domainmetaidindex ON domainmetadata(domain_id);
CREATE TABLE cryptokeys (
id INTEGER PRIMARY KEY,
domain_id INT NOT NULL,
flags INT NOT NULL,
active BOOL,
published BOOL DEFAULT 1,
content TEXT,
FOREIGN KEY(domain_id) REFERENCES domains(id) ON DELETE CASCADE ON UPDATE CASCADE
);
CREATE INDEX domainidindex ON cryptokeys(domain_id);
CREATE TABLE tsigkeys (
id INTEGER PRIMARY KEY,
name VARCHAR(255) COLLATE NOCASE,
algorithm VARCHAR(50) COLLATE NOCASE,
secret VARCHAR(255)
);
CREATE UNIQUE INDEX namealgoindex ON tsigkeys(name, algorithm);
初始化sqlite3
mkdir -p /etc/powerdns/
sqlite3 /etc/powerdns/pdns.sqlite3 < /usr/share/doc/pdns-backend-sqlite/schema.sqlite3.sql
chmod +r /etc/powerdns
配置pdns
nano /etc/powerdns/pdns.conf
写入
launch=gsqlite3
gsqlite3-database=/etc/powerdns/pdns.sqlite3
local-address=<!!你的地址!!>:53
allow-axfr-ips=0.0.0.0/0
slave=yes
allow-notify-from=0.0.0.0/0
allow-dnsupdate-from=0.0.0.0/0
allow-unsigned-notify=yes
解释:由于我们正在配置pdns权威服务器,地址可以选一个你自己子网你喜欢的、比如说我在172.16.3.53
当然监听这种地址需要在网卡上创建一个新ip
对于op来说 可以在web管理界面 选择网络 新建一个接口 区域lan 设备br-lan 地址为172.16.3.53
对于监听53端口、你的本地dnsmasq可能会劫持这个端口
在此我给出的解决方案是关闭dnsmasq
service dnsmasq stop
service dnsmasq disable
然后由于我的dnsmasq会不知道怎么着复活 我写了一个脚本来按死他
nano /root/stop_dnsmasq_if_running.sh
#!/bin/sh
# 检查 dnsmasq 是否在运行在端口53上
if netstat -tlunpa | grep ':53 ' | grep -q 'dnsmasq'; then
service dnsmasq stop
fi
crontab -e
* * * * * /root/stop_dnsmasq_if_running.sh
这个的意思是一个定时脚本 每分钟检测一下 如果他开着 就给他关掉
启动pdns
service pdns restart
配置自己的子域
pdnsutil create-zone ts.dn11 ns1.ts.dn11
其中ts换成你想用的域名
pdnsutil edit-zone ts.dn11
edit-zone会唤醒叫editor的编辑器,如果你没有这个叫editor的编辑器 可以写一下环境变量
nano /etc/profile
添加一行
export EDITOR=/usr/bin/nano
(op的nano默认安装位置在这里、其他你想配的自由发挥)
source /etc/profile
打开edit-zone后 写入
; Warning - every name in this file is ABSOLUTE!
$ORIGIN .
ts.dn11 3600 IN SOA ns1.ts.dn11 hostmaster.ts.dn11 2023093018 60 30 604800 60
ts.dn11 3600 IN NS ns1.ts.dn11.
ns1.ts.dn11 3600 IN A 172.16.3.53
ts.dn11 60 IN A 172.16.3.1
解释:SOA记录里第一个值是你域名权威服务器所在的NS、第二个为邮箱、第三个为流水号(格式YYYYMMDD+2位顺序号)(如果你不改的话pdns会自动帮你顺延流水号)、第四个为刷新间隔、第五个为重试间隔、第六个为过期时间长、第七个为TTL(生存时间值、意为缓存过期时间、设置为60s)
最后一行就是给你的域名加一个A解析
验证
dig a ts.dn11 @172.16.3.53 -p 53
如果返回类似如下内容则成功
root@OP:~# dig a ts.dn11 @172.16.3.53 -p 53
; <<>> DiG 9.18.16 <<>> a ts.dn11 @172.16.3.53 -p 53
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 58804
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;ts.dn11. IN A
;; ANSWER SECTION:
ts.dn11. 60 IN A 172.16.3.1
;; Query time: 0 msec
;; SERVER: 172.16.3.53#53(172.16.3.53) (UDP)
;; WHEN: Sun Oct 15 18:55:04 CST 2023
;; MSG SIZE rcvd: 52
配置TLD域、拉取同步
内网用户需要访问 http://172.16.7.102:8083/login (账号密码dn11)来配置自己的域名权威的ns指向
点击dn11域、点击 add record 、添加两条记录
ns1.ts A 172.16.3.53
ts NS ns1.ts.dn11.
之后点击 save 然后点击 apply changes
解释:ns1是你本地自己启的域名权威服务器的地址
然后回到本地 输入
pdnsutil create-zone dn11
创建dn11域
pdnsutil edit-zone dn11
修改里面的soa值为
dn11 300 IN SOA a.root.dn11 hostmaster.dn11 1 60 60 604800 60
解释:流水号填小 便于拉取上游的同步
然后写数据库启用主从同步
sqlite3 /etc/powerdns/pdns.sqlite3
进入sqlite命令行
先启用看头
sqlite> .header yes
sqlite> select * from domains;
id|name|master|last_check|type|notified_serial|account|options|catalog
1|ts.dn11|||NATIVE||||
2|dn11|||NATIVE||||
里面大概也许是这样、然后写数据库同步上游
UPDATE domains
SET master = '172.16.7.53', type = 'SLAVE'
WHERE name = 'dn11';
写完按 ctrl + D 退出sqlite命令行
然后使用
pdns_control retrieve dn11
强制拉取一下dn11的记录
最后看下自己的记录有没有被同步
root@OP:~# pdnsutil list-zone dn11
检查一下
root@OP:~# dig ns ts.dn11 @172.16.3.53 -p 53
; <<>> DiG 9.18.16 <<>> ns ts.dn11 @172.16.3.53 -p 53
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 7351
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;ts.dn11. IN NS
;; ANSWER SECTION:
ts.dn11. 60 IN NS 172.16.3.53.
;; Query time: 0 msec
;; SERVER: 172.16.3.53#53(172.16.3.53) (UDP)
;; WHEN: Sun Oct 15 19:12:09 CST 2023
;; MSG SIZE rcvd: 61
配置pdns_recursor
nano /etc/powerdns/recursor.conf
写入
# 接受哪些IP的查询请求,0.0.0.0/0表示全部
allow-from=0.0.0.0/0
# 本地监听的接口IP地址
local-address=172.16.255.53:53 172.16.255.53:5300
# 关闭dnssec功能,4.5版本后默认开启
dnssec=off
dont-query=
forward-zones-recurse=dn11=172.16.3.53,.=223.5.5.5
解释:
本地监听的ip地址这里使用anycast、同样的你需要在你的网卡里加一个ip为172.16.255.53(监听5300的原因是、如果路由路径上有人开了dnsmasq、那么这个53请求会被劫持)
并且宣告
root@OP:~# cat /etc/bird.conf
.........
# 宣告 172.16.3.0/24 段
protocol static {
ipv4 {
table BGP_table;
import all;
export none;
};
# 只是为了让BGP的路由表里出现这条路由,不要担心 reject
# 这个动作其实无所谓,reject 这个动作并不会被发到其他 AS
# 后续将在导出到 master4 的时候删除这条路由,本地也不会有这一条
# 请修改为你自己要宣告的段
route 172.16.3.0/24 reject;
route 172.16.255.53/32 reject;
}
.........
root@OP:~# service bird restart
dont-query=的意思是允许内网地址进行查询(默认是禁止的、所以这里填空)
forward-zones-recurse=dn11=172.16.3.53,.=223.5.5.5
这个递归配置项的意思是:如果请求到了dn11这个TLD就去请求你自己搭的ns、如果不是这个域就当公网处理转发给公网dns 223.5.5.5
然后重启
service pdns-recursor restart
最后测试一下、请求一下网里存在的域名
root@OP:~# dig op.iraze.dn11 @172.16.255.53 -p 53
; <<>> DiG 9.18.16 <<>> op.iraze.dn11 @172.16.255.53 -p 53
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 4037
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;op.iraze.dn11. IN A
;; ANSWER SECTION:
op.iraze.dn11. 60 IN A 172.16.2.2
;; Query time: 39 msec
;; SERVER: 172.16.255.53#53(172.16.255.53) (UDP)
;; WHEN: Sun Oct 15 19:23:32 CST 2023
;; MSG SIZE rcvd: 58
2.docker拉镜像 装pdns-admin web界面管理
[root@gs-fedora Pdns]# cat docker-compose.yml
version: "3"
services:
pdns:
image: zhonger/pdns:latest
restart: always
ports:
- "172.16.7.53:53:53/tcp"
- "172.16.7.53:53:53/udp"
environment:
- PDNS_launch=gsqlite3
- PDNS_gsqlite3_database=/var/lib/powerdns/pdns.sqlite3
- PDNS_webserver_address=0.0.0.0
- PDNS_webserver_allow_from=0.0.0.0/0
- PDNS_allow_axfr_ips=0.0.0.0/0,::1
- PDNS_allow_dnsupdate_from=0.0.0.0/0,::1
- PDNS_allow_notify_from=0.0.0.0/0,::0
- PDNS_also_notify=172.16.3.53
- PDNS_master=yes
- PDNS_api=yes
- PDNS_api_key=0F34664B2C9CA2E1B84C5A6B4605C968
volumes:
- /etc/localtime:/etc/localtime:ro
- ./powerdns:/var/lib/powerdns
command: /bin/bash ./up.sh
privileged: true
db:
image: mysql:latest
environment:
- MYSQL_ALLOW_EMPTY_PASSWORD=yes
- MYSQL_DATABASE=powerdnsadmin
- MYSQL_USER=pdns
- MYSQL_PASSWORD=my_pdns
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- ./pda-mysql:/var/lib/mysql
privileged: true
app:
image: zhonger/powerdns-admin:latest
restart: always
depends_on:
- db
- pdns
ports:
- "8083:80"
logging:
driver: json-file
options:
max-size: 50m
volumes:
- /etc/localtime:/etc/localtime:ro
environment:
- SQLALCHEMY_DATABASE_URI=mysql://pdns:my_pdns@db/powerdnsadmin
- GUNICORN_TIMEOUT=60
- GUNICORN_WORKERS=2
- GUNICORN_LOGLEVEL=DEBUG
- OFFLINE_MODE=False # True for offline, False for external resources
privileged: true
[root@gs-fedora Pdns]# cat up.sh
service system-resolve stop
ip addr add 172.16.7.53 dev eno1
这个key是我随便写的、你可以自己生成一个
PDNS_api_key=0F34664B2C9CA2E1B84C5A6B4605C968
在powerdns admin settings pdns中填写这个key 填好后 在上层的PowerDNS server configuration & statistics里能看到一系列pdns的字段
配置dns分流 MosDNS
装包
opkg update
opkg install mosdns
注意不要装 luci-app-mosdns 我感觉不好用
改配置
nano /etc/mosdns/config.yaml
log:
level: info
file: "/tmp/mosdns.log"
api:
http: "0.0.0.0:9091"
include: []
plugins:
- tag: main_sequence
type: sequence
args:
# hdu内网dns解析
- matches: qname hdu.edu.cn
exec: forward 192.168.0.1:53
# dn11内网dns解析
- matches: qname dn11
exec: forward 172.16.255.53:5300
# 其他dns解析
- matches: "!qname hdu.edu.cn dn11"
exec: forward 223.5.5.5:53
# 启动端口和ip
- tag: udp_server_2
type: udp_server
args:
entry: main_sequence
listen: "172.16.3.13:53"
- tag: tcp_server_2
type: tcp_server
args:
entry: main_sequence
listen: "172.16.3.13:53"
同样的 启动需要你br-lan网卡里加一个 172.16.3.13这个ip地址
service mosdns restart
